7.6 Câmera LookAt
Câmera LookAt é o nome dado ao frame de câmera virtual \(\{P_{\textrm{eye}}, \hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\) construído a partir das seguintes informações:
- Um ponto \(P_\textrm{eye}\) que corresponde à posição da câmera no espaço do mundo;
- Um ponto \(P_\textrm{at}\) que corresponde à posição aonde a câmera está olhando, também no espaço do mundo28.
- Um vetor \(\mathbf{v}_\textrm{up}\) utilizado para indicar a direção “para cima” da câmera. Geralmente esse vetor é a direção \((0,1,0)\).
A figura 7.25 ilustra esses elementos, incluindo os vetores \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\) que formam a base ortonormal da câmera.
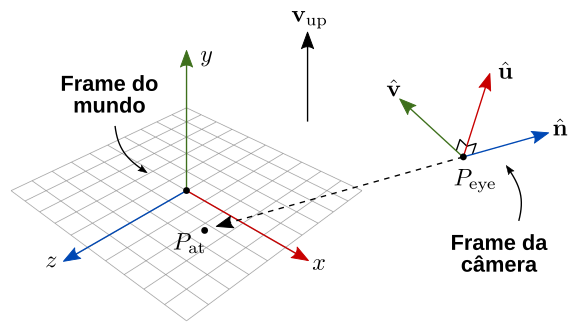
Figura 7.25: Frame da câmera, representado em relação ao mundo.
O sistema de coordenadas da câmera segue a regra da mão direita. Note que a câmera está olhando na direção \(-\hat{\mathbf{n}}\) no espaço do mundo, que corresponde à direção do eixo \(z\) negativo da câmera.
Inicialmente, não temos a base ortonormal \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\). Só temos as seguintes informações (ilustradas na figura 7.26):
- A posição da câmera, \(P_\textrm{eye}\);
- A posição para onde a câmera deve ser direcionada, \(P_\textrm{at}\);
- O vetor \(\mathbf{v}_\textrm{up}\), que vamos considerar como sendo o vetor \((0,1,0)\).
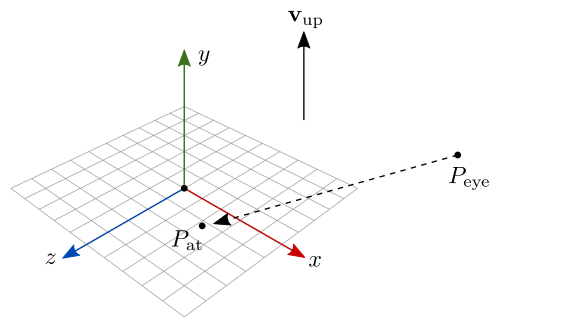
Figura 7.26: Parâmetros de uma câmera LookAt.
Através dessas informações construiremos a base \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\). Com a base e o ponto de referência (\(P_{\textrm{eye}}\)) temos o frame completo para criar a matriz de visão \(\mathbf{M}_{\textrm{view}}\). Como vimos anteriormente, a matriz de visão representa uma mudança de frame: do espaço do mundo para o espaço da câmera.
Construindo o vetor n
Para construir a base ortonormal, primeiro fazemos \(P_{\textrm{eye}}-P_{\textrm{at}}\) para obter o vetor que aponta na direção contrária da direção de visão. Esse vetor é então normalizado para obter \(\hat{\mathbf{n}}\) (figura 7.27):
\[ \hat{\mathbf{n}}=\frac{P_{\textrm{eye}}-P_{\textrm{at}}}{|P_{\textrm{eye}}-P_{\textrm{at}}|}. \]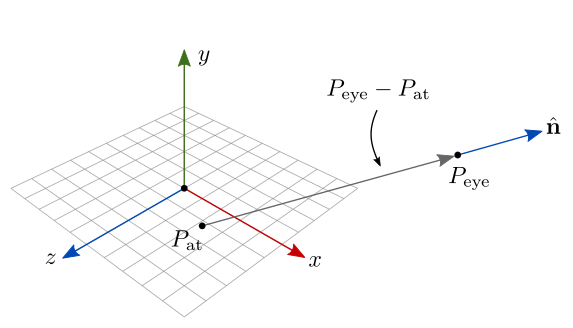
Figura 7.27: Construção do vetor n da câmera LookAt.
Note que \(\hat{\mathbf{n}}\) está sendo representado em coordenadas do espaço do mundo. Em relação à câmera, \(\hat{\mathbf{n}}\) torna-se o vetor \(\hat{\mathbf{k}}=(0,0,1)\), isto é, a direção do eixo \(z\) positivo da câmera (direção para trás da câmera).
Construindo o vetor u
Agora que temos \(\hat{\mathbf{n}}\), o segundo passo é calcular o produto vetorial \(\mathbf{v}_{\textrm{up}} \times \hat{\mathbf{n}}\) e normalizar o resultado. Com isso obtemos o vetor \(\hat{\mathbf{u}}\) perpendicular ao plano formado por \(\mathbf{v}_{\textrm{up}}\) e \(\hat{\mathbf{n}}\) (figura 7.28):
\[ \hat{\mathbf{u}}=\frac{\mathbf{v}_{\textrm{up}} \times \hat{\mathbf{n}}}{|\mathbf{v}_{\textrm{up}} \times \hat{\mathbf{n}}|}. \]
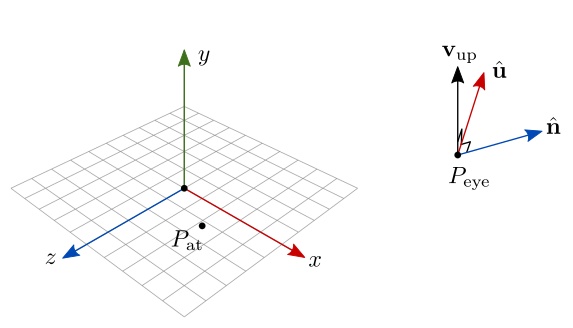
Figura 7.28: Construção do vetor u da câmera LookAt.
No frame da câmera, \(\hat{\mathbf{u}}\) corresponde ao vetor \(\hat{\mathbf{i}}=(1,0,0)\), isto é, a direção do eixo \(x\) da câmera (direção à direita).
Construindo o vetor v
Embora \(\hat{\mathbf{u}}\) seja perpendicular a \(\hat{\mathbf{n}}\) e a \(\mathbf{v}_{\textrm{up}}\), ainda não temos uma base ortonormal pois \(\mathbf{v}_{\textrm{up}}\) não é necessariamente perpendicular a \(\hat{\mathbf{n}}\). Na figura 7.28, \(\mathbf{v}_{\textrm{up}}\) e \(\hat{\mathbf{n}}\) formam um ângulo menor que \(90^{\circ}\).
Para obter um vetor que seja mutuamente ortogonal a \(\hat{\mathbf{n}}\) e \(\hat{\mathbf{u}}\), basta calcularmos o produto vetorial \(\hat{\mathbf{n}} \times \hat{\mathbf{u}}\). O resultado é \(\hat{\mathbf{v}}\) (figura 7.29) que já está normalizado pois \(\hat{\mathbf{n}}\) e \(\hat{\mathbf{u}}\) também têm comprimento 1.
\[ \hat{\mathbf{v}}=\hat{\mathbf{n}} \times \hat{\mathbf{u}}. \]
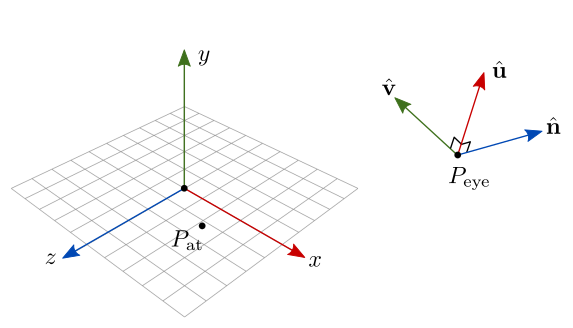
Figura 7.29: Construção do vetor v da câmera LookAt.
Note que, em relação à câmera, \(\hat{\mathbf{v}}\) corresponde ao vetor \(\hat{\mathbf{j}}=(0,1,0)\), isto é, o eixo \(y\) da câmera (direção para cima).
Os vetores \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\) formam a base ortonormal da câmera, representados em relação ao espaço do mundo.
Construindo a matriz de visão
Para a construção da matriz de mudança de frame, vamos relembrar primeiro a matriz de mudança de base.
A matriz com colunas formadas pelos vetores \(\{T(\mathbf{\hat{\mathbf{i}}}),T(\mathbf{\hat{\mathbf{j}}}),T(\mathbf{\hat{\mathbf{k}}})\}\) representa uma mudança da base \(\{\hat{\mathbf{i}}, \hat{\mathbf{j}}, \hat{\mathbf{k}}\}\) para a base transformada. A transformação \(T\) é uma composição de rotações (por exemplo, \(\mathbf{R}_z\mathbf{R}_y\mathbf{R}_x\)), que tem o efeito de rodar a base original para a nova.
O que temos atualmente é a base \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\). Esses vetores estão representados em relação ao espaço do mundo. Se estivessem representados em relação ao espaço da câmera, a base seria \(\{\hat{\mathbf{i}}, \hat{\mathbf{j}}, \hat{\mathbf{k}}\}\). Então, se construirmos a matriz \(\mathbf{R}\) de mudança de base,
\[ \mathbf{R}= \begin{bmatrix} u_{11} & v_{12} & n_{13} & 0 \\ u_{21} & v_{22} & n_{23} & 0 \\ u_{31} & v_{32} & n_{33} & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}, \] tal matriz representa a mudança do espaço da câmera para o espaço do mundo. Não é bem o que queremos. Gostaríamos da matriz que faz a transformação inversa, isto é, que converte coordenadas do mundo para a câmera. Entretanto, vamos prosseguir com \(\mathbf{R}\) da forma como está. Ao final poderemos calcular a matriz inversa da transformação completa, para finalmente obter \(\mathbf{M}_{\textrm{view}}\).
Com a matriz \(\mathbf{R}\), a base \(\{\hat{\mathbf{i}}, \hat{\mathbf{j}}, \hat{\mathbf{k}}\}\) no espaço da câmera é transformada por rotações para resultar na base \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\) representada no espaço do mundo. Isso é ilustrado na figura 7.30.
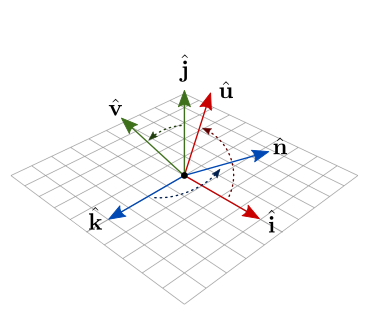
Figura 7.30: Rotação da base representada no espaço da câmera, para a base representada no espaço do mundo.
Além da base, um frame também precisa de um ponto de referência. Esse ponto de referência é o próprio \(P_\textrm{eye}\), que representa a origem \(O\) no espaço da câmera. \(P_\textrm{eye}\) é o deslocamento necessário para mover a origem do espaço da câmera para sua posição no espaço do mundo. Em outras palavras, temos uma transformação de translação que pode ser representada pela matriz
\[ \mathbf{T}= \begin{bmatrix} 1 & 0 & 0 & P_{\textrm{eye}_x} \\ 0 & 1 & 0 & P_{\textrm{eye}_y} \\ 0 & 0 & 1 & P_{\textrm{eye}_z} \\ 0 & 0 & 0 & 1 \end{bmatrix}. \]
Fazendo a composição das transformações, temos
\[ \mathbf{M} = \mathbf{T} \mathbf{R} \] \[ \mathbf{M}= \begin{bmatrix} 1 & 0 & 0 & P_{\textrm{eye}_x} \\ 0 & 1 & 0 & P_{\textrm{eye}_y} \\ 0 & 0 & 1 & P_{\textrm{eye}_z} \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} u_{11} & v_{12} & n_{13} & 0 \\ u_{21} & v_{22} & n_{23} & 0 \\ u_{31} & v_{32} & n_{33} & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}. \] A figura 7.31 ilustra como a matriz de transformação \(\mathbf{M}\) converte coordenadas do espaço da câmera para o espaço do mundo, que é o equivalente a rodar a base \(\{\hat{\mathbf{i}}, \hat{\mathbf{j}}, \hat{\mathbf{k}}\}\) para \(\{\hat{\mathbf{u}}, \hat{\mathbf{v}}, \hat{\mathbf{n}}\}\) (matriz de rotação \(\mathbf{R}\)), e então transladar a origem \(O\) para \(P_{\textrm{eye}}\) (matriz de translação \(\mathbf{T}\)).
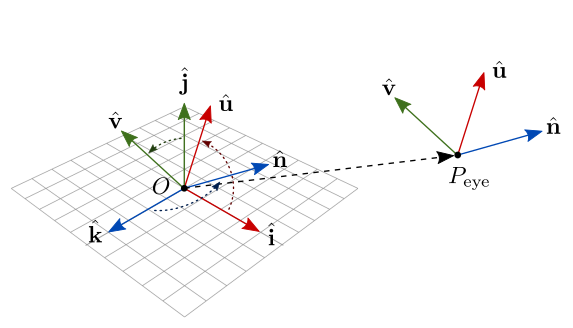
Figura 7.31: Mudança do espaço da câmera para o espaço do mundo.
Para obter \(\mathbf{M}_{\textrm{view}}\), basta calcularmos a inversa de \(\mathbf{M}\). Lembre-se que a inversa de uma matriz de rotação é a sua transposta, e a inversa da translação por \(P_{\textrm{eye}}\) é a translação por \(-P_{\textrm{eye}}\). Portanto,
\[ \begin{align} \mathbf{M}_{\textrm{view}} &= \mathbf{M}^{-1}\\ &= (\mathbf{T} \mathbf{R})^{-1}\\ &= \left( \begin{bmatrix} 1 & 0 & 0 & P_{\textrm{eye}_x} \\ 0 & 1 & 0 & P_{\textrm{eye}_y} \\ 0 & 0 & 1 & P_{\textrm{eye}_z} \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} u_{11} & v_{12} & n_{13} & 0 \\ u_{21} & v_{22} & n_{23} & 0 \\ u_{31} & v_{32} & n_{33} & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \right)^{-1}\\ &= \begin{bmatrix} u_{11} & v_{12} & n_{13} & 0 \\ u_{21} & v_{22} & n_{23} & 0 \\ u_{31} & v_{32} & n_{33} & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}^{-1} \begin{bmatrix} 1 & 0 & 0 & P_{\textrm{eye}_x} \\ 0 & 1 & 0 & P_{\textrm{eye}_y} \\ 0 & 0 & 1 & P_{\textrm{eye}_z} \\ 0 & 0 & 0 & 1 \end{bmatrix}^{-1}\\ &= \begin{bmatrix} u_{11} & u_{21} & u_{23} & 0 \\ v_{12} & v_{22} & v_{33} & 0 \\ n_{13} & v_{23} & n_{33} & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 & 0 & -P_{\textrm{eye}_x} \\ 0 & 1 & 0 & -P_{\textrm{eye}_y} \\ 0 & 0 & 1 & -P_{\textrm{eye}_z} \\ 0 & 0 & 0 & 1 \end{bmatrix}\\ &= \begin{bmatrix} u_{11} & u_{21} & u_{23} & -\hat{\mathbf{u}}\cdot P_{\textrm{eye}} \\ v_{12} & v_{22} & v_{33} & -\hat{\mathbf{v}}\cdot P_{\textrm{eye}} \\ n_{13} & v_{23} & n_{33} & -\hat{\mathbf{n}}\cdot P_{\textrm{eye}} \\ 0 & 0 & 0 & 1 \end{bmatrix}. \end{align} \]
A biblioteca GLM possui a função glm::lookAt, definida em cabeçalho glm/gtc/matrix_transform.hpp:
glm::mat4 glm::lookAt(glm::vec3 const& eye, glm::vec3 const& center, glm::vec3 const& up);
glm::dmat4 glm::lookAt(glm::dvec3 const& eye, glm::dvec3 const& center, glm::dvec3 const& up);glm::lookAt gera a matriz \(\mathbf{M}_{\textrm{view}}\) de uma câmera LookAt, dados os parâmetros \(P_{\textrm{eye}}\) (eye), \(P_{\textrm{at}}\) (center) e \(\mathbf{v}_\textrm{up}\) (up).
Internamente, a função chama glm::lookAtRH para gerar o frame baseado na regra da mão direita. O conteúdo dessa função é dado a seguir:
template<typename T, qualifier Q>
GLM_FUNC_QUALIFIER mat<4, 4, T, Q> lookAtRH(vec<3, T, Q> const& eye, vec<3, T, Q> const& center, vec<3, T, Q> const& up)
{
vec<3, T, Q> const f(normalize(center - eye));
vec<3, T, Q> const s(normalize(cross(f, up)));
vec<3, T, Q> const u(cross(s, f));
mat<4, 4, T, Q> Result(1);
Result[0][0] = s.x;
Result[1][0] = s.y;
Result[2][0] = s.z;
Result[0][1] = u.x;
Result[1][1] = u.y;
Result[2][1] = u.z;
Result[0][2] =-f.x;
Result[1][2] =-f.y;
Result[2][2] =-f.z;
Result[3][0] =-dot(s, eye);
Result[3][1] =-dot(u, eye);
Result[3][2] = dot(f, eye);
return Result;
}Na linha 4, f (vetor “forward”) é equivalente ao nosso \(-\hat{\mathbf{n}}\).
Na linha 5, s (vetor “side”) é o nosso vetor \(\hat{\mathbf{u}}\), calculado como \(-\hat{\mathbf{n}} \times \mathbf{v}_\textrm{up}\), que é o mesmo que \(\mathbf{v}_\textrm{up} \times \hat{\mathbf{n}}\), seguido de uma normalização.
Na linha 6, u é o nosso vetor \(\hat{\mathbf{v}}\), calculado como \(\hat{\mathbf{u}} \times -\hat{\mathbf{n}}\), que é o mesmo que \(\hat{\mathbf{n}} \times \hat{\mathbf{u}}\).
Nas linhas 9 a 21 é montada a matriz Result, que é a matriz \(\mathbf{M}_{\textrm{view}}\). Internamente, a GLM armazena as matrizes no formato column-major, o que significa que o primeiro índice é a coluna, e o segundo índice é a linha. Levando isso em consideração, observe que a matriz resultante é de fato:
\[ \begin{align} \mathbf{M}_{\textrm{view}} &= \begin{bmatrix} u_{11} & u_{21} & u_{23} & -\hat{\mathbf{u}}\cdot P_{\textrm{eye}} \\ v_{12} & v_{22} & v_{33} & -\hat{\mathbf{v}}\cdot P_{\textrm{eye}} \\ n_{13} & v_{23} & n_{33} & -\hat{\mathbf{n}}\cdot P_{\textrm{eye}} \\ 0 & 0 & 0 & 1 \end{bmatrix}. \end{align} \]
O ponto “at” também é chamado de “center” ou “target.”↩︎